Dict Object in Python
Contents
Try to answer these question.
Whatare dictionaries and sets good for?
How are dictionaries and set the same?
What is the overhead when using a dictionary?
How can I optimize the performance of a dictionary?
How does Python use dictionaries to keep track of namespace?
Dictionary object type – mapping from hashable object to object
In the implemenation, Python don’t choose Red-Black Tree as the basic data structure but Hash Table with a special technology – Open Addressing.
About open addressing:
In computer science, lazy deletion refers to a method of deleting elements from a hash table that uses open addressing. In this method, deletions are done by marking an element as deleted, rather than erasing it entirely. Deleted locations are treated as empty when inserting and as occupied during a search. – Wikipedia
There three kinds of slots in the table:
Unused.
me_key==me_value==NULL
Does not hold an active (key, value) pair now and never did. Unused can transition to Active upon key insertion. This is the only case in whichme_keyis NULL, and is each slot’s initial state.Active.
me_key!= NULL andme_key!= dummy andme_value!= NULL Holds an active (key, value) pair. Active can transition to Dummy upon key deletion. This is the only case in whichme_value!= NULL.Dummy.
me_key== dummy andme_value== NULL
Previously held an active (key, value) pair, but that was deleted and an active pair has not yet overwritten the slot. Dummy can transition to Active upon key insertion. Dummy slots cannot be made Unused again (cannot haveme_keyset to NULL), else the probe sequence in case of collision would have no way to know they were once active.
Here, Python define the entry data type of dict in python PyDictObejct. A entry is like a paire (key, value). To avoid calculating the hash value of me_key, me_hash used as a cached value for it.
|
|
To ensure the lookup algorithm terminates, there must be at least one Unused slot (NULL key) in the table.
The value ma_fill is the number of non-NULL keys (sum of Active and Dummy);
ma_used is the number of non-NULL, non-dummy keys (== the number of non-NULL values == the number of Active items).
To avoid slowing down lookups on a near-full table, we resize the table when it’s two-thirds full.
|
|
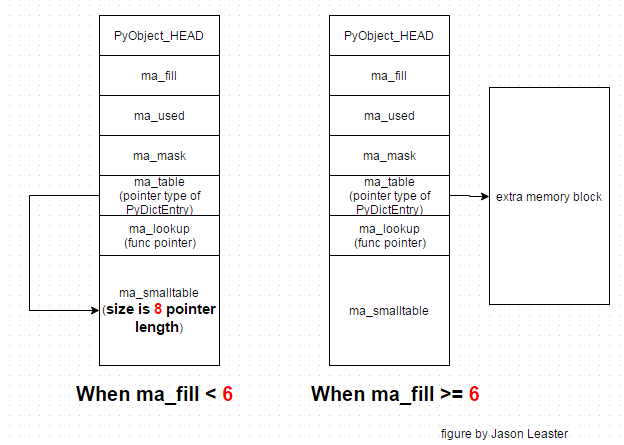
PyDict_MINSIZE is the minimum size of a dictionary. This many slots are allocated directly in the dict object.
(in the ma_smalltable member).
It must be a power of 2, and at least 4. 8 allows dicts with no more than 5 active entries to live in ma_smalltable (and so avoid an additional malloc); instrumentation suggested this suffices for the majority of dicts (consisting mostly of usually-small instance dicts and usually-small dicts created to pass keyword arguments).
|
Here defined a array ma_smalltable which store 8 PyDictEntry.ma_table points to ma_smalltable for small tables, else to
additional malloc’ed memory. ma_table is never NULL!
This rule saves repeated runtime null-tests in the workhorse getitem and setitem calls.
I draw a figure to make the idea easy to be understand.
The question is coming. When Python will resize the diction table of that object?
The answer is in function dictresize in file Object/dictobject.c
|
|
Attention, once mp-ma_fill bigger or equal to (2/3)mp->ma_mask+1 and we have finished a insert operation(mp->ma_used > n_used), we should resize the container(ma_table) of the dictionary.
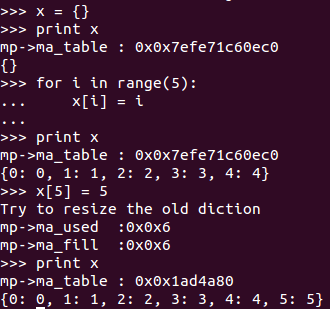
Yes, we should resize the dictionary object if there have 6 or more object in the container but not 8.
Here is the result of hacking.
Actually, dummy PyDictObject is just a PyStringObject in Python. Initially, dummy is a pointer in C but it finally comes to a PyStringObject after initialization of PyDictObject first time.
It’s important to note that resizing can happen to make a hash table larger or smaller. This is , if sufficiently many element of a hash table are deleted, the table can be scaled down in size. However, resizing only happens during an insert.
|
|
Initialization Part
There are two ways to create a dict: PyDict_New() is the main C API function,
and the tp_new slot maps to dict_new(). In the latter case we
can save a little time over what PyDict_New does because it’s guaranteed
that the PyDictObject struct is already zeroed out.
Everyone except dict_new() should use EMPTY_TO_MINSIZE (unless they have an excellent reason not to).
|
|
Photo By Jason Leaster

作者: Jason Leaster
来源: http://jasonleaster.github.io
链接: http://jasonleaster.github.io/2016/02/04/dict-object-in-python/
本文采用知识共享署名-非商业性使用 4.0 国际许可协议进行许可