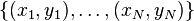Two month ago, I decide to do a project about machine learning. So, I get start to learn machine learning and implemment some algorithms of ML. I find that there is a course in MIT – 6.034 Artificial Intelligence which contain a lot of funny labs. That will help me to learn ML.
I don’t want to write a lot of analysis article about this course like what I have done in 6.008 . So, I just push my solution which also is incompletement onto github. If anyone interesting in this lab, you could touch me and I would like to communicate with you about these labs if I’m not busy.
What you should know is that the version of this labs is updated in 2015.
This blog will talk about the theory and implementation about famouse concept in machine learning – Boosting.
All algorithms are implemented in Python.
There are two main tasks which people want to finish with Machine Learning.
Classification
Regression
There are a lot of other ways to do it but now we focus on boosting algorithm. You know that it’s a fantastic way to make our work done.
Adaboost for classification
If you never hear about adaboost, I recommend you to finish the 7-th lab in MIT 6.034. It will help you a lot to understand what I’m taking about. But this lab didn’t build adaboost completely. So, I implement it individually.
Give the input training samples which have tag with it.
where x[i] is the feature of the i-th sample point and y[i] is the label (soemtimes we call it as tag) with the sample point.
In this algorithm, there are only two different label of samples {-1, +1}.
Some classifier like decision tree also can work correctly about classification. But it’s also easy to overfitting. So, we can’t use it in some special situation. Instread of using decision tree, we use decision stump which is a special type of decision tree which’s depth is only one. So we call it as decision stump.
Yoav Freund and Robert Schapire create this algorithm AdaBoost which means adaptive boosting.
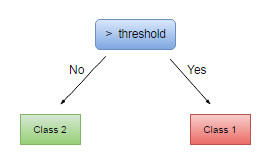
Test case:
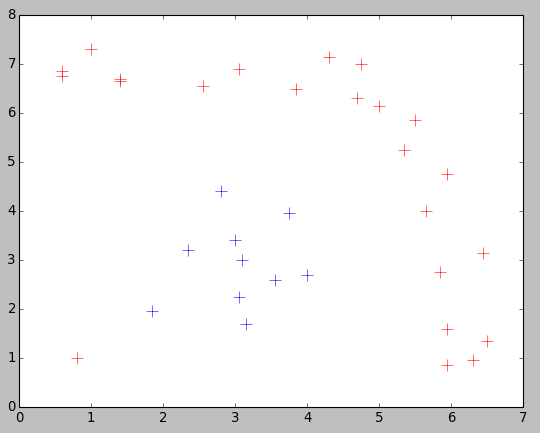
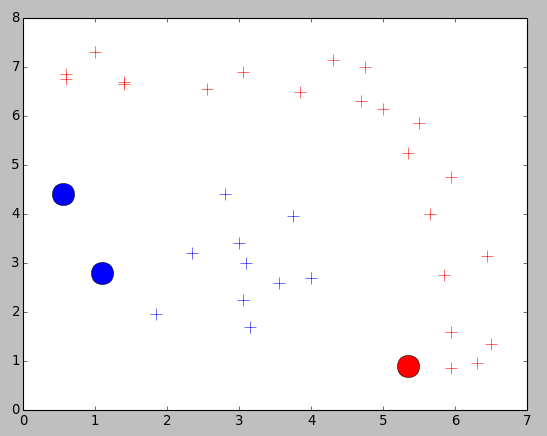
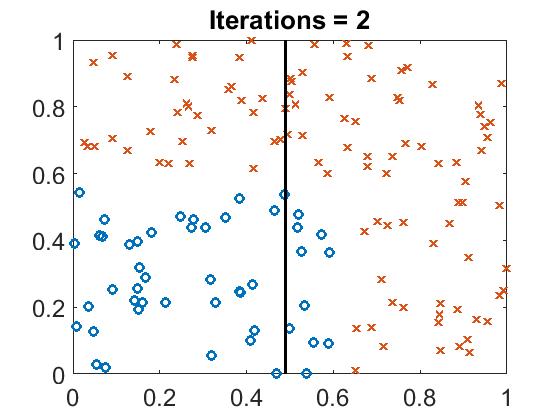
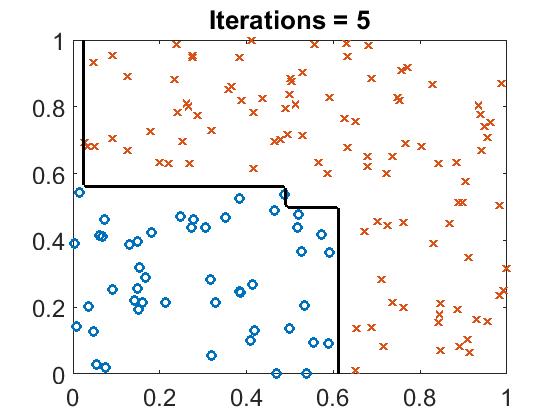
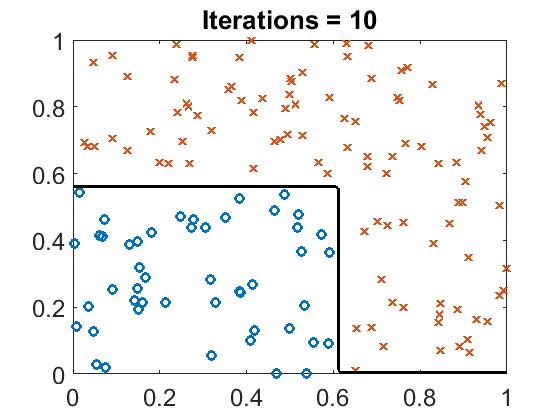
There are training points with two different label. What if we input a point which’s type is unkown, what the result will be?
The test result is below there:
Just create a object of class Adaboost with your training samples with label. like this:
1
2
3
4
5
6
7
8
9
import adaboost
a = AdaBoost(Original_Data, Tag)
# The up bound of training time to avoid the algorithm won't stop for not meeting the training accuracy.
times = 5
a.train(times)
a.prediction(UnkownPoints)
API prediction() of class AdaBoost will return the result of prediction according to the model. All job done.
You could find other test case in my repository in github.
There is an assignment about AdaBoost in Stanford CS 229, which will ask student to implement stump booster. But I don’t really understand the skeleton of that source code. I think there must be something worng with that matlab script stump_booster.m. The week classifier can’t lost the direction information.
1
2
3
4
5
6
7
8
9
10
%%% !!! Don't forget the important variable -- direction
API given by the course materials:
function[ind, thresh] = find_best_threshold(X, y, p_dist)
function[theta, feature_inds, thresholds] = stump_booster(X, y, T)
API of my solution:
function[ind, thresh, direction] = find_best_threshold(X, y, p_dist)
function[theta, feature_inds, thresholds, directions] = stump_booster(X, y, T)
Run boost_example.m, you will see the classifier line with different iteration.
Boosting Tree
We have knew to use AdaBoost to do classification. Boosting Tree will help us to do regression.
We also use decision stump as the weak classifier. But implementation of decision stump in this algorithm is not the same as that in AdaBoost.
There are ten samples in my test module:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Original_Data = numpy.array([
[2],
[3],
[4],
[5],
[6],
[7],
[8],
[9],
[10],
[1]
]).transpose()
ExpVal = numpy.array([
[5.70],
[5.91],
[6.40],
[6.80],
[7.05],
[8.90],
[8.70],
[9.00],
[9.05],
[5.56]
]).transpose()
The expected value of Original_Data[i] is ExpVal[i]. The input is from 1 to 10. How about to predict the output when the input is 1 or 11?
Let’s test it. Here is the result:
Just used 11 weak classifier to construct a stronger classifier to do the regressio. The output is reasonable.
In this days, I work as an intern for Alibaba. To be honest, it totally a bad time for the beginning days. More awful fact to me is that my mentor do his job mostly in Java and I have to pick it up as quickly as possible. It’s totally a stranger for me about Java. What I have to say is that thanks god and my mentor. He is so nice and never blame me for my problem. You know that I suffer pressure heavily for I learned nothing but time wasted in this two weeks. I asked for help from human resource manager and hope to find someone guide me to walk out this shadow. Bo who is my mentor. He understand me and know my feeling. Bo encourage me and try to let me believe things will be better. Today, I face to a problem which I think is very naive but I didn’t show the solution to a leader of a department very well. And I could feel that he doubt about my ability in programming. I feel shame about he ask me that “Do you have programming in C or C++ for ten thousand lines ?”.
Nowadays, people use the social networks like Facebook, Weibo, Qzone and so on. That social networks make you feel that you live with others who have no relationship with you in real life. And more and more people pay a lot of time to refresh the website or the software which is programed for social networks. So did I …
The most important fact is that the message comes from the social networks didn’t help us a lot. If you pay the same time to read a classical book or work hard on your projects, you will get more.
But you choose to refresh your social networks and fall into it. You may know that you are wasting time but you still focus on it. Something like drug … yes, you are drugging but in a different way. Social networks also let you indulge yourself with idle and feel hollow after you have waste a lot of time on that. Day after day, you get nothing but only feel more and more hollow. You know that people live well from the message which the social networks feed you.
Times always change, there will be more and more temptation. But the thing we should know is that we should learn to distinguish what’s important and what just kill us by wating our time.
I delete all message I posted on Weibo and Qzone. In previous days, I followed more than two hundred people in Weibo. To be honest, people I followed most don’t know me and have nothing with my own life. Why I follow them just because I curious about what happened on their daily life. In the beginning, it’s funny. But now I delete them all. Yep, I wake up to reality! It have onthing with my life! I shouldn’t waste time on others who isn’t important for me. WE DO HAVE OUROWN LIFE.
I like a motto from steve jobs.
If you want to live your life in a creative way, as an artist, you have to not look back too much. You have to be willing to take whatever you’ve done and whoever you were and throw them away. People think focus means saying yes to the thing you’ve got to focus on. But that’s not what it means at all. It means saying not to the hundred other good ideas that there be. You have to pick carefully. I’m actually as proud of the things we haven’t done as the things I have done. Innovation is saying no to 1,000 things.
In << The C++ Programming Language >> , there is a exercise for learner who is studying C++. It’s that student should write a program in C++ to manipulate “character picture”, something like this.